What Is Perplexity and Burstiness? The Two Numbers That Determine If Your Writing Sounds Human

Quick Answer
What is perplexity and burstiness in AI writing?
Perplexity measures how predictable your word choices are. Burstiness measures how much your sentence lengths vary. AI text scores low on both: predictable words, uniform rhythm. Human writing scores higher on both because people make unexpected word choices and naturally vary sentence length.
On this page
- 1. What perplexity actually measures
- 2. What burstiness actually measures
- 3. Why technical writers get flagged more than anyone
- 4. How to improve both scores without ruining your writing
- 5. The limits of perplexity and burstiness as detection signals
- 6. How do AI detectors calculate perplexity and burstiness?
- 7. Frequently asked questions
The AI detection score came back at 71%. I had written every word myself. I knew this because I remembered writing it, sentence by sentence, over about four hours on a Tuesday morning. I reread the piece three times looking for some obvious tell I had missed. Nothing. So I did what anyone would do: I Googled “why does human writing get flagged as AI” and spent the next hour clicking through documentation I was not prepared to understand.
Eventually I found two words that explained almost everything. Perplexity. Burstiness. These are the core mathematical signals that most AI detectors use as a first layer of analysis. They are not about meaning or ideas. They measure sentence rhythm and word predictability. Once I understood what each one actually measured, I went back and looked at my writing, and the problem was immediately obvious. Understanding perplexity and burstiness in AI writing detection explains nearly every false positive you have seen or will see.
What does perplexity actually measure in AI writing?
Perplexity measures how predictable each word is given the words that came before it. Low perplexity means the next word was obvious. High perplexity means the next word was surprising, which is the signal detectors associate with human authorship.
To understand why this works as a detection signal, you need to know one thing about how large language models generate text: they predict the next most likely word given the prior context. That is the mechanism, not a metaphor. The model calculates probability distributions across its vocabulary and selects the highest-probability token. So text produced by a language model has naturally low perplexity, because every word chosen was statistically probable given what came before it. The model is doing exactly what a low-perplexity score measures.
Human writers do not work this way. People make unexpected choices. They draw on specific memories, personal observations, and individual voice. Those things produce word combinations that are statistically unusual. Consider the difference between these two sentences:
Low perplexity
“The meeting was scheduled for Tuesday.”
Every word follows naturally from the one before it. A detector predicts this easily.
Higher perplexity
“The meeting was rescheduled because the client had food poisoning from a conference burger.”
Nobody predicted “conference burger.” That specificity is structurally human, statistically unusual, and raises the perplexity score for that sentence.
There is a paradox here that trips up a lot of writers. Formal, precise vocabulary produces lower perplexity, not higher. Using the exact right technical term where a simpler word would do looks more AI-like to detectors. A sentence using “instantiation” where most writers would say “example” is precise, and precision is the pattern. Predictable precision is still predictable. What raises perplexity is unexpected specificity, personal voice, and the kind of word choice that comes from having actually experienced something rather than describing a category of experiences.
Perplexity is calculated per sentence and then averaged across the document. A single highly specific sentence does not rescue a document full of predictable prose. The signal is cumulative. That is why one interesting paragraph in an otherwise flat article barely moves the overall score.
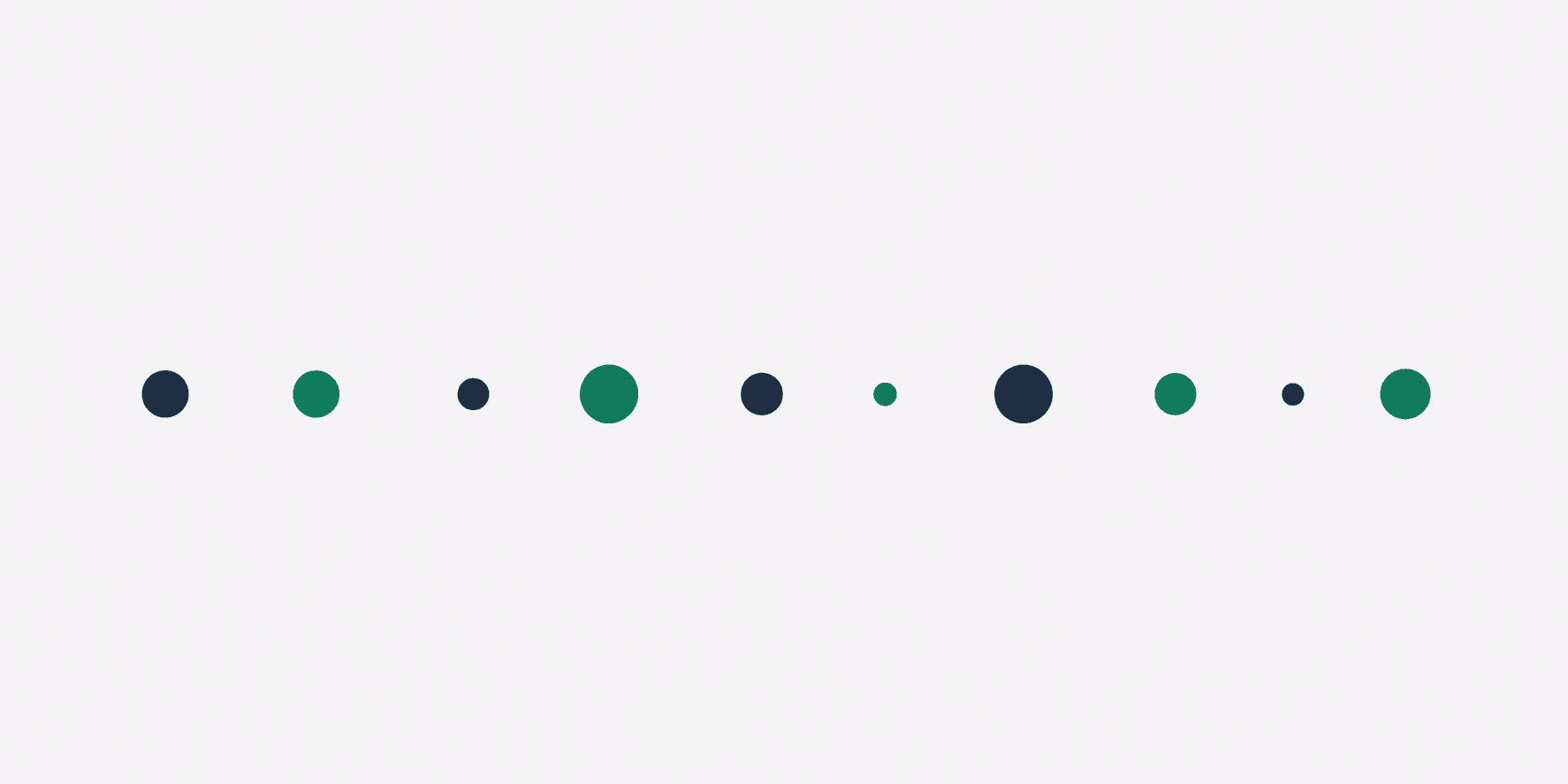
What does burstiness actually measure?
Burstiness measures how much your sentence lengths vary. The formula is the standard deviation of sentence lengths divided by the mean sentence length. Human writing scores 0.65 to 0.85. AI writing typically scores below 0.30.
When I found out my burstiness score was 0.18 after the 71% flagging incident, I went back and actually counted the words in each sentence for three paragraphs. Every sentence landed between 14 and 19 words. Every single one. I write clean, deliberate sentences. I always have. I thought that was a virtue. Turns out it is also a statistical signature that looks identical to what a language model produces when it has not been specifically instructed to vary its rhythm.
The fix is structural, not about vocabulary. Here is what low burstiness actually looks like in practice:
Low burstiness (uniform rhythm)
“The model processes each sentence in sequence. It assigns a probability to each word. The score reflects the average predictability across the text. A lower score indicates higher similarity to AI output.”
All four sentences: 9, 8, 11, 9 words. Standard deviation near zero. Burstiness: very low.
Higher burstiness (natural variation)
“The model processes each sentence. It assigns a probability score to each word in sequence, working forward from the beginning of the document and averaging across the full text to produce a single perplexity number. Lower is worse. High similarity to AI output.”
Sentence lengths: 5, 35, 3, 6 words. Wide variation. Burstiness: much higher.
The content is nearly identical in both examples. The rhythm is not. That rhythm difference is what burstiness detects, and it is also what makes the second version read more like a person wrote it, because people do not naturally produce sentences of uniform length when they are actually thinking through a problem.
GPTZero’s original detection model, published by Edward Tian in January 2023, was built on perplexity and burstiness as its two primary signals. According to GPTZero’s own documentation on perplexity and burstiness, ZeroGPT, Copyleaks, and Originality.ai all use variants of these signals as part of their detection layers. This is why improving your burstiness score moves your results across multiple tools at once. The underlying math is the same.
Target a burstiness score above 0.60. Above 0.65 is where most natural human writing lands. If you are scoring below 0.30, the sentence length problem is almost certainly the first thing to fix before anything else.
| Metric Type | Low Score Meaning (AI Signal) | High Score Meaning (Human Signal) | Typical Target Range |
|---|---|---|---|
| Perplexity | Words are highly predictable and follow common sequences. | Words are unexpected, specific, or unique. | Varies by tool model |
| Burstiness | Sentences are uniform in length with repetitive rhythm. | Sentences vary significantly in length and structure. | 0.65 to 0.85 |
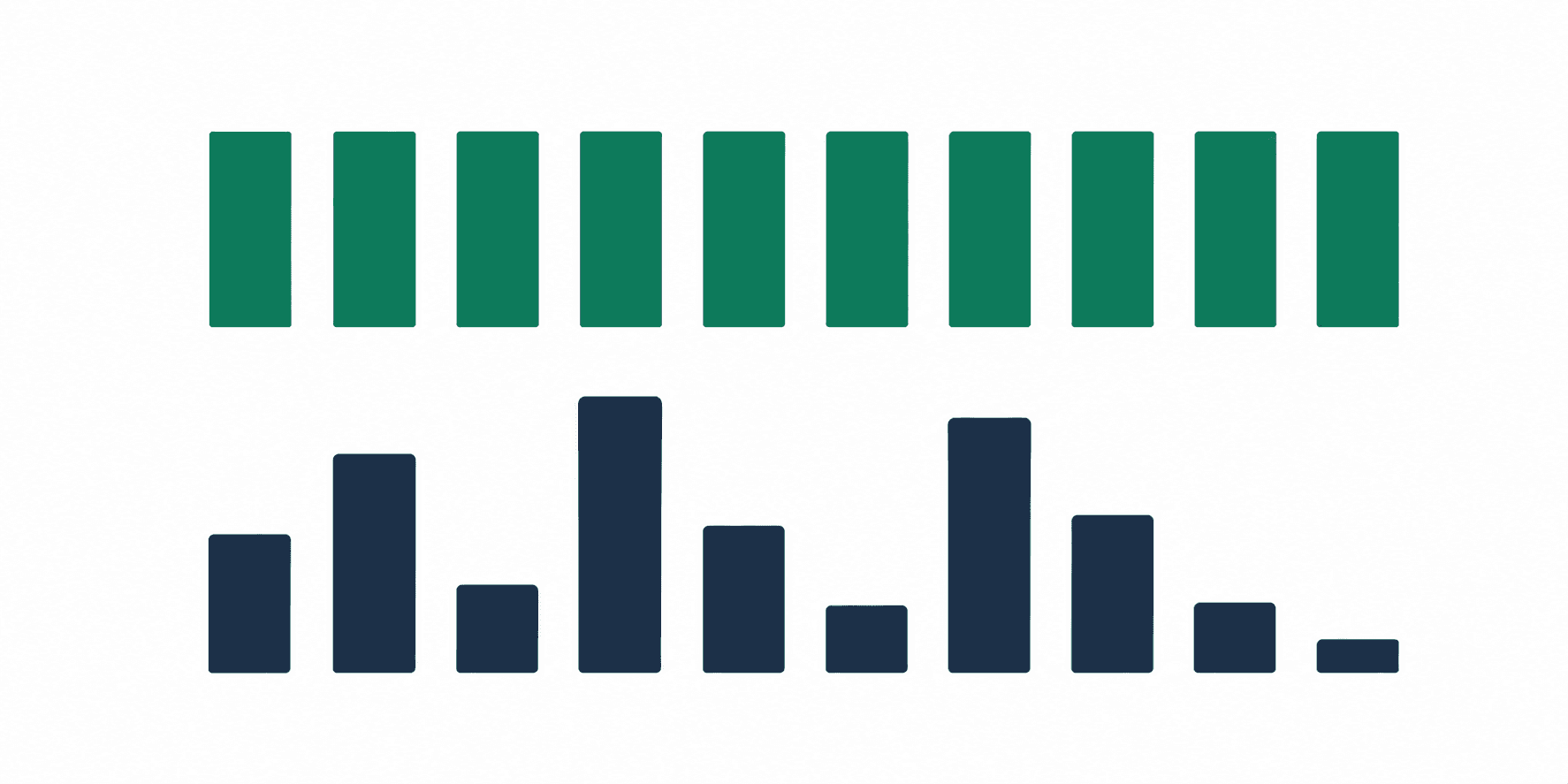
Why do technical writers and non-native speakers get flagged most?
Technical writers get flagged because professional clarity produces exactly the statistical profile that AI detectors are trained to catch. The same is true for non-native English speakers, academics, and legal writers.
Technical writing is supposed to be precise, consistent, and predictable. That is not a flaw. It is the entire goal. A safety manual where sentence length varies wildly is a poorly written safety manual. A legal brief where word choices are “surprising” is a problem, not a feature. These forms of writing deliberately produce low burstiness and low perplexity, because that is what professional clarity looks like in statistical terms. The detector cannot distinguish between deliberate formal precision and AI output, because the numbers are the same.
Non-native English speakers face this problem for a different reason. Writers working in a second language tend to use more conservative vocabulary, safer words they know are correct rather than unexpected choices that might be wrong. Sentences are shorter. Structures are more uniform. Both of those patterns lower the burstiness score and the perplexity score at the same time. Pangram Labs documented this disparity in their 2025 research, finding that perplexity-based detectors flag non-native writers at rates substantially higher than native writers producing equivalent content.
Research Case Study: Non-native English Writers and AI False Positives (Pangram Labs)
A 2025 study by Pangram Labs analyzed essays written by native and non-native English speakers. The researchers found that popular perplexity-based detectors flagged over 50% of writing by non-native speakers as AI-generated.
This disparity occurs because non-native writers use a more limited vocabulary and more uniform sentence structures. These patterns lower both perplexity and burstiness, triggering false positives.
This is the part of AI writing detection that nobody talks about honestly. The writers who get flagged most often are the ones who have worked hardest to write clearly. The precision that makes technical writing useful and the caution that characterizes second-language writing are both punished by these tools. A content marketer writing informal blog posts in their first language almost never triggers these signals. An engineer writing documentation in their fourth language triggers them constantly.
I am not sure what to do with that observation except state it plainly. The false positive rate is not evenly distributed. Understanding why helps calibrate how much weight to put on any individual AI detection score.
How do you improve perplexity and burstiness without making your writing worse?
Four techniques actually move the scores. None of them require you to write badly. They require you to write differently in specific, targeted ways rather than hoping that general editing fixes the underlying statistical problem.

Sentence length variation
This is the burstiness fix. Go through your draft and deliberately break rhythm. Cut one long sentence into two short ones. Combine two short sentences into one that takes its time, uses a subordinate clause, circles back to the original point, and lands somewhere specific. Do this across the whole document, not just in one section. Burstiness is calculated across the full text. One bursty paragraph in a flat article barely moves the score. The variation needs to be consistent throughout.
Specific personal detail
“I tested this on a $3,200 client brief last March” has higher perplexity than “I tested this on a large project.” Real specificity creates statistically unusual word combinations. The detector is measuring predictability. Exact dollar amounts, named dates, specific locations, and personal observations are harder to predict than categories. “The client” is predictable. “A regional insurance company in Tulsa that had been using the same CMS since 2014” is not. The second version is also more useful to the reader. This technique improves your AI detection score and the quality of your writing at the same time.
Opinions and genuine uncertainty
Phrases like “I am not sure this applies in every case” or “the result surprised me” or “I expected this to work and it did not” raise perplexity without changing the substance of what you are saying. Language models are trained to be confident and helpful. Hedged, uncertain, genuinely opinionated language is statistically unusual in their training data, which means it reads as more human to the detection layer. This does not mean adding fake uncertainty. It means being honest about what you actually do not know, which is something most professional writing strips out in the editing process.
Fragments
One-sentence paragraphs and sentence fragments increase burstiness immediately. Not rhetorically. Mathematically. A three-word sentence dropped between two eighteen-word sentences creates a spike in the standard deviation of sentence lengths that moves the burstiness calculation in the right direction. Fragments are also a recognized pattern in informal and semi-formal human prose. Like this. The detector sees a short sentence and registers variation. That is all it needs.
If you would rather not hunt for low-burstiness sections manually, the Vortenza Humanizer targets 29 structural AI writing patterns, including uniform sentence rhythm, predictable vocabulary, and em dash overuse. Running your content through it before checking scores is faster than doing the sentence-level audit yourself. Quillbot’s explainer on burstiness and perplexity also covers the practical mechanics of how these signals interact if you want a second source on the underlying math.
Before rewriting anything, use the Vortenza AI Detection Checker to see which sections are actually triggering. Rewriting everything when only two paragraphs are the problem is wasted time. Diagnose first.
What are the limits of perplexity and burstiness as detection signals?
These signals are imperfect, and treating any score from any tool as a definitive verdict is a mistake. The same article can score 8% AI on GPTZero and 69% AI on Originality.ai, because each tool weights perplexity and burstiness differently and uses different baseline models.

I ran the same piece through GPTZero and Originality.ai on the same day and got scores 61 percentage points apart. Neither tool changed. The text did not change. The tools just measure different things and weight them differently. That level of disagreement between professional detection tools is not a minor calibration issue. It means neither score is reliable enough to be treated as a verdict on a specific piece of writing.
The reliability problem gets worse as models improve. Fine-tuned language models in 2025 and 2026 can produce text with perplexity levels comparable to human writing when prompted to do so. Pangram Labs documented in their 2025 research that perplexity-based detectors cannot self-improve with new training data because they are fixed statistical models. The detectors get updated on the detection side, but the core signal has diminishing reliability as the models it was designed to catch get better at avoiding it.
Under the hood, detectors use natural language processing models to evaluate n-gram probability. This evaluation measures predictive text patterns and Shannon entropy to determine if the word selection randomness matches human writing or follows a rigid statistical pattern.
What does not change is the false positive rate for human writers. These signals were designed to catch AI text. They also catch concise, clear, formal human text, and that has been true since the original GPTZero model launched in January 2023. Turnitin suppresses AI detection scores below 20% on their platform because their own internal testing found reliability at that range too low to report to educators. That is a tool creator acknowledging the limitations of their own detection in writing.
Understanding perplexity and burstiness changes how you read these results. A high AI score on a piece of formal technical writing means the writing is precise and consistent, which is exactly what it should be. It does not mean the writing is AI-generated. A high score on informal content means the rhythm is too uniform or the word choices are too predictable, and those are things you can fix.
The guide on bypassing AI detection in 2026 covers the full practical approach to improving scores across multiple tools. If you are confusing plagiarism detection with AI detection, those are different problems with different tools, and the plagiarism checking guide explains the distinction.
How do AI detectors calculate perplexity and burstiness?
AI detectors calculate perplexity by measuring the statistical probability of each word using a baseline language model. They calculate burstiness by measuring the standard deviation of sentence lengths across the entire document.
By analyzing these two metrics together, detection algorithms create a probability profile of the content. If the sentence lengths are uniform and the word choices follow the most probable sequences, the detector flags the text as machine-generated.
Frequently asked questions
What is a good burstiness score for human writing?+
What is a good perplexity score for human writing?+
Why does formal writing get flagged as AI?+
Can you improve burstiness after writing?+
Do all AI detectors use perplexity and burstiness?+
Does adding specific details increase perplexity?+
Why do non-native English writers get flagged more?+
Is there a tool to check my burstiness score specifically?+
Does burstiness matter more than perplexity for AI detection?+
What is the difference between perplexity and burstiness?+
What is the relation between AI writing temperature and perplexity?+
Can AI bypassers automatically fix perplexity and burstiness?+
Do search engines like Google penalize low perplexity or low burstiness?+
Why does academic writing naturally score low in perplexity?+
Knowing what perplexity and burstiness actually measure changes how you read detector results. A high AI score on formal technical writing means the writing is clear and consistent, which is what it is supposed to be. That is a feature of the writing, not evidence of AI authorship. A high score on something you wrote informally means the sentence rhythm is too uniform or the word choices are too predictable, and both of those are fixable in a single revision pass.
Check your scores before rewriting anything with the Vortenza AI Detection Checker. If burstiness is the problem, the Vortenza Humanizer handles the structural patterns. The full AI detection guide covers every signal beyond just these two. And if you are conflating AI detection with plagiarism checking, they are different problems entirely: the plagiarism guide explains what each tool actually measures.
One concrete action before your next revision: count the words in each sentence across one paragraph. If they are all within five words of each other, that is your burstiness problem right there. Fix the rhythm first. The perplexity usually follows.
About this guide
Written by the Vortenza Editorial Team. We build free SEO writing tools and practical guides for content marketers, writers, and developers. The 71% false positive described here was a real one. Technical sources: GPTZero documentation, Pangram Labs 2025 research, Originality.ai blog.
Related tools
Related Guides
How to Bypass AI Detection in 2026
AIHow to Check Plagiarism Before Publishing
AIAI Detectors Are Guessing: What the Research Actually Shows
AIPrompt Engineering Guide 2026: Techniques That Actually Work
AIChatGPT vs Claude vs Gemini vs DeepSeek: Which AI Wins in 2026?
AIClaude API Pricing 2026: Complete Cost Breakdown